
In this previous post, I introduced myself to multiple change-point detection by replicating inflation charts from Thomas Piketty’s Capital in the 21st Century. That use case was a bit novel. It was great to get familiar with the changepoint R package and how the algorithms work, but I wanted to go a step further and understand how it might be used in operations. Change-point detection is a brilliant partner to statistical control charts. When using statistical control charts for sales trends, defect rates, or cycle times, a common challenge is determining the right historical period in which to calculate control limits. Go back too far, and the limits don’t represent the modern operating environment. If you don’t go back far enough, the limits might be too wide to be helpful.
The Cass Freight Index is a measure of North American freight demand.
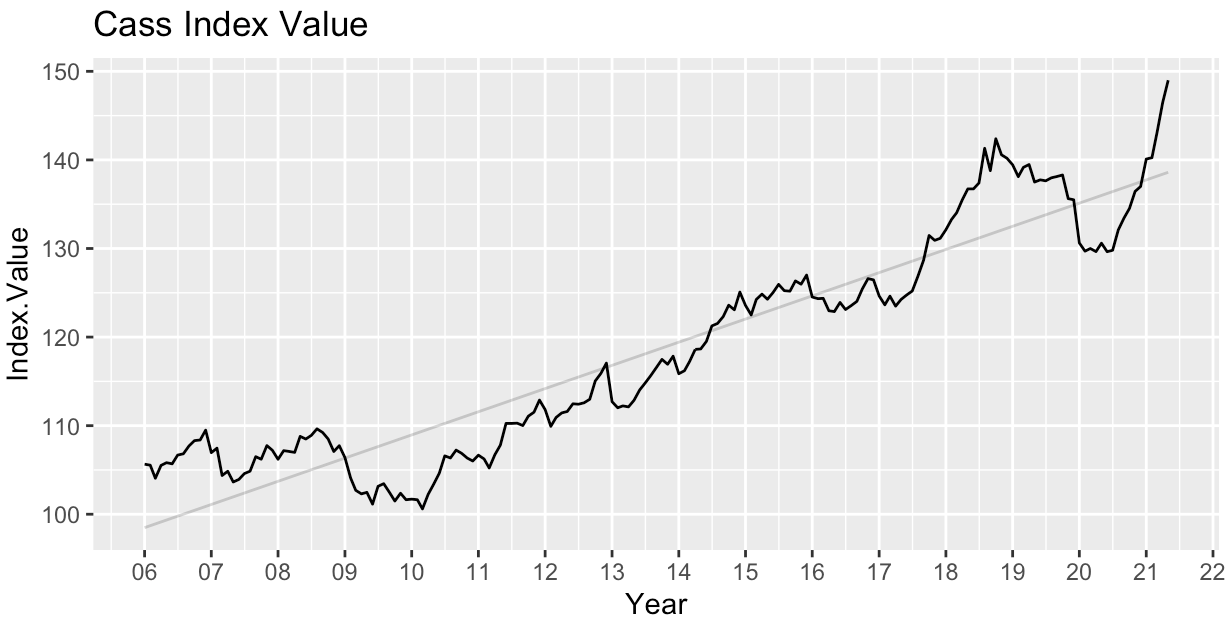
All things being equal, higher demand generally implies higher costs (for shippers). As freight demand changes, the incentive structure for participants in the market also changes and agents will adjust their strategy accordingly. As such, it’s important to know, relatively speaking, how loose or tight freight demand is. Here are four control charts for the year over year change in the monthly Cass Freight Index:
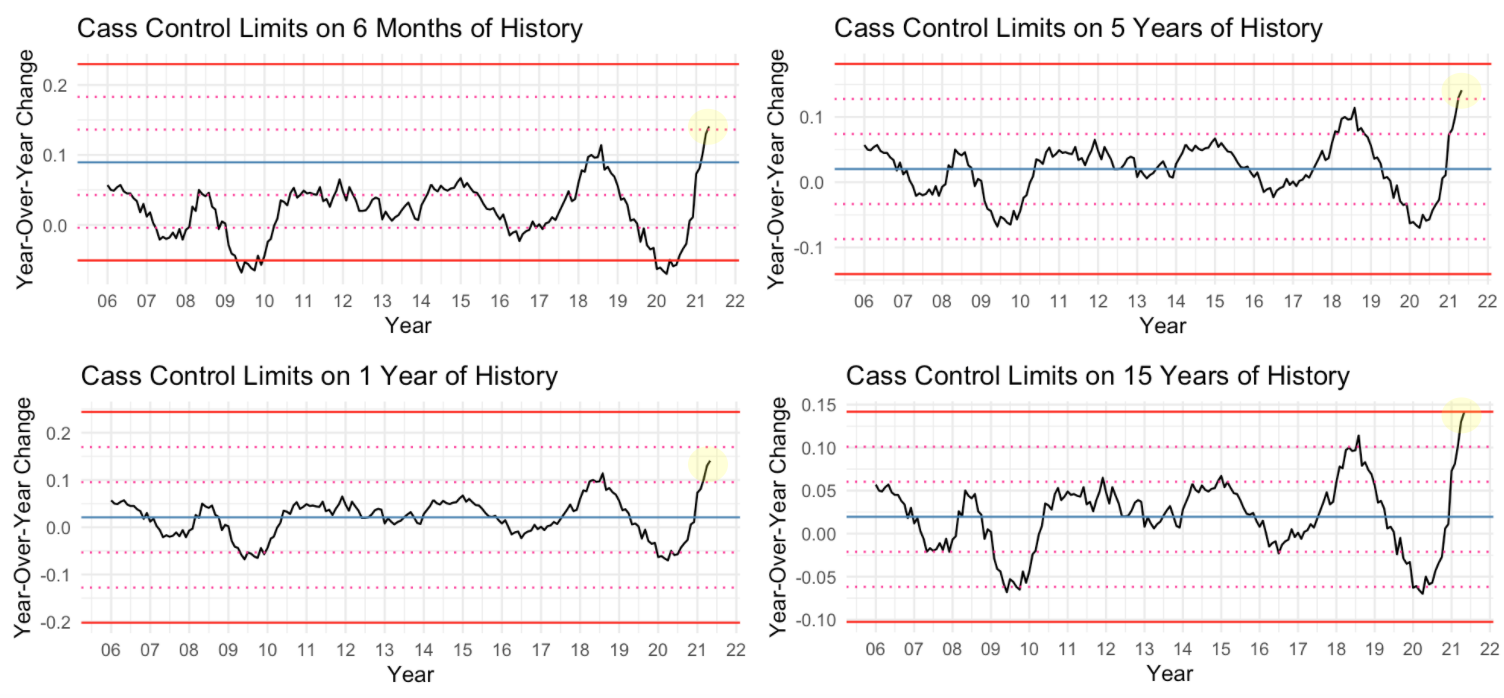
Calculated on 6 months of history, your control limits show you that you are 1 standard deviation above average. Clearly, that is poor context for decision-making. On the other end of the spectrum, control limits calculated on 15 years of history show you are at 3 standard deviations above average. Knowing that year-over-year numbers in May 2021 are highly influenced by the “unprecedented” pandemic of 2020, this level also seems like poor context. So, what’s the right date for the middle ground?
After quite a bit of parameter tuning, these are the multiple change points I thought were appropriate:
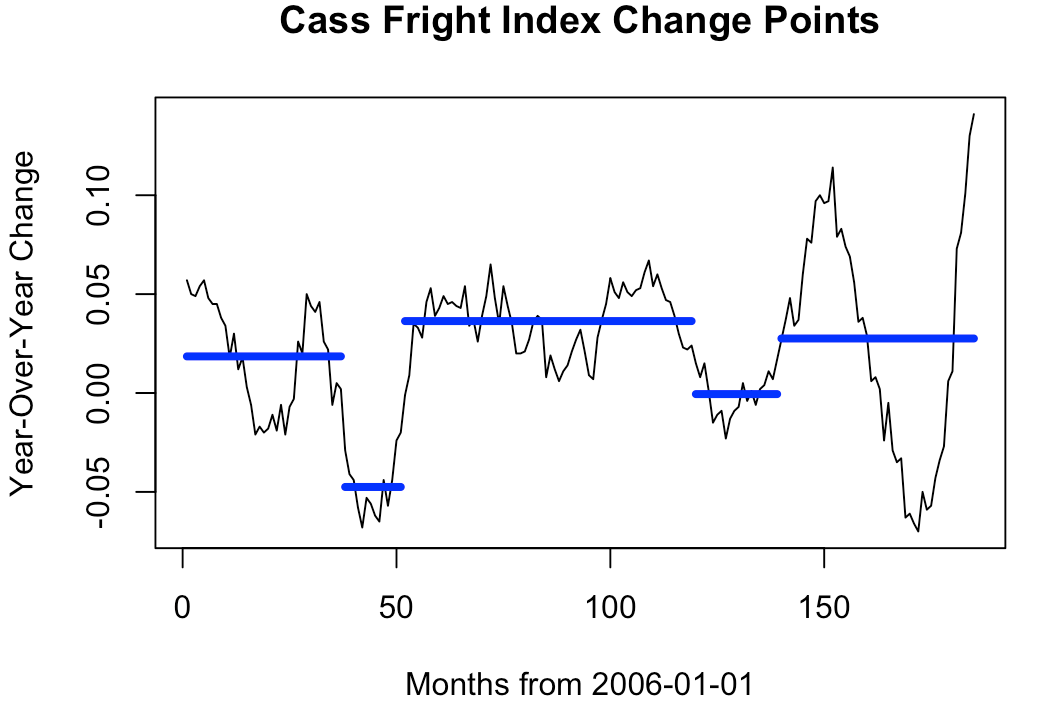
I suppose I am assuming that the most modern “era” of freight demand started well before the pandemic. In the chart, the final change point is at the beginning of 2017. Starting with the Index line chart above, my initial thinking was that 2006-2010 was “medium volatility”, 2010-2015 was “continuous growth / low volatility”, 2015-2017 was “stability”, and 2017 to 2021 was “high volatility”. So, when I used a certain set of parameters and the change point detection algorithm identified 4 change points creating 5 eras, it felt right.
Quick technical detour. Changepoint detection involves a bit of subjectivity since you need to define the penalty parameter (a higher penalty generally reduces the number of change points). This was even called out in the documentation for the changepoint package: “The choice of appropriate penalty is still an open question and typically depends on many factors including the size of the changes and the length of segments, both of which are unknown prior to analysis.” That’s too vague and too uncertain. I needed a heuristic, a methodology. Here’s how I approached it.
I made the assumption that if you have back-to-back periods (or even relatively close back-to-back periods) that are change points, your penalty is too low (and your time between change points should be longer). So, I looped through penalty values from 1 to 100 rerunning the change point algorithm. For each penalty value I checked whether there was any segment less than or equal to 2 periods – if so, I kept increasing the penalty. This seemed to be a good balance between fitting the data to my narrative and using a random, pre-defined penalty value.
Back to the Index. Below, I display our retroactive analysis. By combining these tools, we use 4 years of history to calculate the statistical control limits. Yes, the year-over-year change in May 2021 is higher than it has been in 15 years (probably ever). However, the adjusted control limits now let me know that relative to our current operating environment, the year-over-year increase isn’t off the rails (yet).
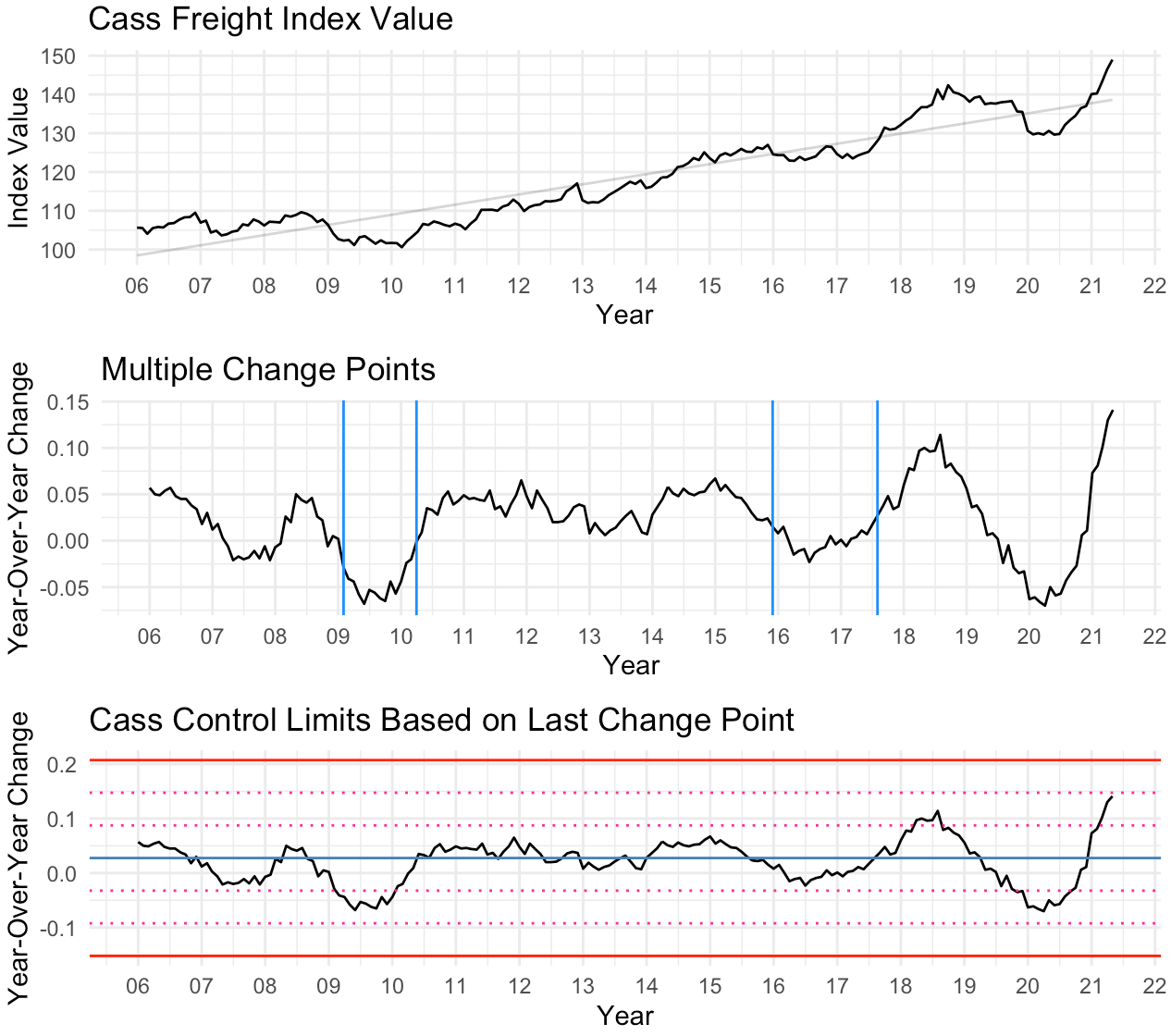
Statistical control charts are anything but new. Changepoint detection algorithms, also, weren’t created yesterday. Yet, it’s rare to see these tools used together. Over and over again I see the most value from data analytics coming from the creativity to combine different tools with domain knowledge to generate insight. I think Piketty has it right. You cannot just put data in front of people and expect they will gain clarity about the problem or issue. You need to arrange it in such a way that connects to our intrinsic narrative instincts. At the same time, tools like control charts and change point detection can prevent you from telling a story that perhaps is too far removed from the truth. As Mick Byrne used to tell us over and over again; “you need to find the perfect balance.”
I created a gist to check out if you want to replicate yourself.