
Who is the most polite person you work with and how do you quantify that answer?
For me, it’s a female colleague who works in the West Coast Finance department. Her emails to me are chock full of appreciative words such as…
words = ["thanks", "thank you", "thx", "tks", "please", "pls"]
The occurrence of phrases such as ‘thanks’, ‘thank you’, and ‘please’ in her emails to me happen much more frequently than any other of my coworkers, including the runner up who works in the East Coast Finance department. Measuring politeness in emails turned out to be slightly more vexing than I had originally anticipated. For instance, in order to determine the most polite department, was I to use the mean politeness score* for the individuals in that department or the median politeness score… or something else? If a department has 10 people, of which 8 of them have dismal politeness scores while 2 have outstanding scores… that department deserves a poor standing in the ranks (although calculating the average using the mean might yield a deceptively high politeness score). I want to disregard outliers so the few courteous folks in a department can’t drag up the many rude folks in that department. By this logic, I use median measure of central tendency to score by department.
* Politeness score defined as sum of times a polite word appears in sender emails ÷ count of emails received by that sender
So, if I look at the median politeness score by department, HR is the clear winner… followed by Finance.
[('HR', 1.2575757575757576),
('Customer', 0.97972972972972971),
('Finance', 0.85424710424710426),
('Sales & Marketing', 0.43778801843317972),
('Engineering', 0.38190009124087593),
('Operations', 0.36363636363636365),
('Admin', 0.29999999999999999),
('Systems', 0.29166666666666669),
('Vendor', 0.13664596273291924),
('Misc.', 0.0)]
Overall, across all senders from whom I’ve received emails over the past year, Sept 2015 – Aug 2016, the mean politeness score was 0.89 and the median score 0.52 (highly skewed). For the latter score, that translates to one (1) polite word for every two (2) emails received. Considering the back and forth nature of our email exchanges… I think a score of 0.50 represents an appreciative environment without being inefficient. Anything above 1 is overkill and anything under 0.25 is uncalled for. Note that the median of 0.5 includes Customer emails who received a group score of 0.98 bringing up the overall score).
The Process
Start by downloading your emails to a csv file over the past x months. Despite the onslaught of emails you think you receive throughout the day, I doubt this file will be very big. My file — downloading a years worth of emails — was only 9,418 rows across 19 columns (40MB). For this analysis, I only use 2 columns… Body (the text of the email) and From (the sender from whom I’ve received the email). Unfortunately, my email provider doesn’t easily allow me to include probably the most useful column — date & time. At any rate, I read the csv into a pandas dataframe and specify the polite words (shown way above). Then, I write what is probably a down and dirty, inefficient for loop that outputs a dictionary where the key is the From field and the value is a list containing two fields… [count of nice words in that senders emails, number of emails received from that sender].
# define dictionary to store sender and metrics
counts = {}
# for each sender record list of
# [count of nice words, number of emails received]
for index, row in data.iterrows():
text = row["Body"]
# blank body mail yield a float upon which
# text functions will not work. Skip 'em.
if type(text) == float:
continue
# skip emails from myself
elif row["FromName"] == "Frank Corrigan":
continue
# skip emails from myself
elif row["FromName"] == "Frank X. Corrigan":
continue
else:
# convert all text to lower so won't have
# to differentiate 'Thanks' from 'thanks'
text = text.lower()
# email Body incorporates full email threads.
# find first instance of 'sent' and substr
# from start of text to instance. Not perfect,
# but good enough
stop = text.find('sent')
text = text[0:stop]
# count instances of polite words
nice = sum(text.count(x) for x in words)
# store the name of the sender
sender = row["FromName"]
# if sender already in out output dict, increment
# appopriate metrics to the value list
if sender in counts.keys():
counts[sender][0] += nice
counts[sender][1] += 1
# otherwise, create new sender with appropriate
# metrics
else:
counts[sender] = [nice, 1]
The top of the output counts dictionary looks like this…
{'???': [0, 2],
'AA-ISP': [0, 1],
'Aberdeen Group': [0, 6],
'Aberdeen Research': [0, 1],
'AdExchanger': [5, 5],
'Ahmed I______’: [12, 8] # removing all names for privacy
}
Looking at the above, Ahmed is super polite and Aberdeen Group not polite at all. I can then create a new dictionary where I divide the # of kind words per sender by the number of emails received by sender to get the politeness score I’m looking for. Most scores are less than 1… but some senders really overkill the politeness. For those seeking code, I’ve attached an ipython notebook.
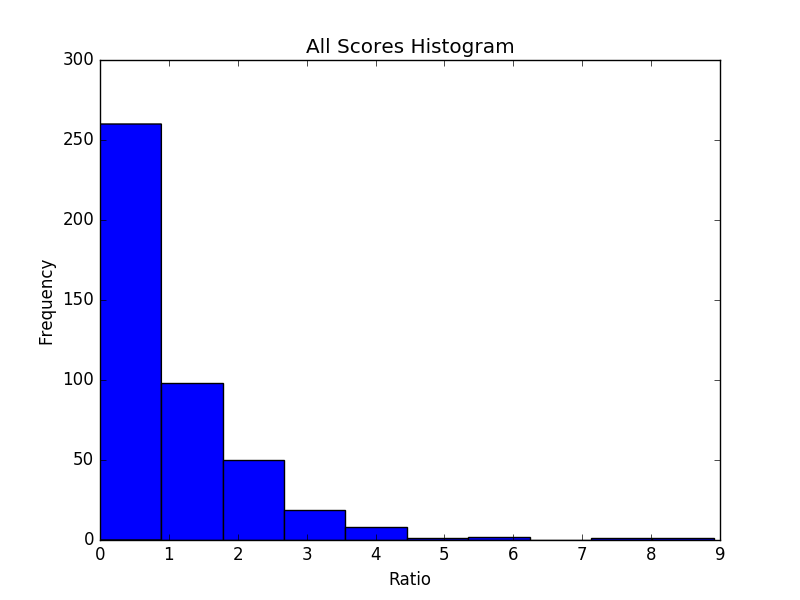
Lastly, I hard coded each of the 440 senders (I removed myself) to a group — HR, Customer, Vendor (like SalesForce or Ecommerce Show USA), Sales & Marketing, Finance, etc. — in order to determine the median politeness score for each department. The below histogram of all politeness scores is representative of most departments.
More Useful Ideas for Text-Mining Emails
Quantifying politeness by sender and department in only my emails is fun, but not very actionable. If we wanted this to be more useful we’d need to start aggregating email text of multiple people and connect that with additional data sources. For instance, if we were able to connect this type of analysis across email data from our sales & marketing team with opportunity win / losses data from our CRM we could understand if more courteous emails lead to more won opportunities. FYI – I can feel (and understand) the twinges of folks who are pondering the dangers associated with this slippery slope of text-mining emails.
I’ve been curious for awhile to see if there is a relationship between how many times a customer name is mentioned across all company email accounts and the operating performance for the customers account. Two opposing hypotheses could be totally plausible. First, I could imagine that a spike in the frequency of a customer’s name across our email network would mean we are having problems with that account… and we should expect to have a subpar margin performance for that month on that account (or act to prevent that). Alternatively, a spike in the frequency of a customer’s name across our email network might indicate that our operators are fully on top of any changes or unexpected conditions for that account and we should expect to see us right at our budgeted margin.
Of course, in order to build this model we’d need to aggregate lots of text from many hundreds of emails on a daily, if not hourly, basis, metadata on account conditions and customer concerns, as well as data from finance on account expectations and actual performance. Not a task for the faint of heart… but the ROI could be there if the analysis resulted in a early detection system for profit-reducing problems in the operation.