
A few months ago, I wanted to collect minutely Uber surge price data over the course of a week between Penn Station, NY. and Union Square, NY. I wrote a python script to call Uber’s API every minute and record the response to a text file (as basic as it gets). Then, I tried to figure out how to run the script for a week straight. I attempted, in a variety of ways, to let my laptop run for the entire week (turn off sleep mode, schedule a cron job, etc.). Every time, the script stopped running for one reason or another. I then turned to AWS. Without a ton of time to learn the platform, I surrendered, and had my friend Colin St. George run the script for me on his server. At the end of the week, he ‘handed’ me the text file so I could create this d3 visualization for Udacity’s Data Visualization with d3.js course.
Fast forward. Last week I came to the end of Miguel Grinberg’s Flask Mega-Tutorial which reignited my desire to get a virtual private server up and running myself to collect data continuously from the web. In the final post of the series, he uses a VPS (with CentOS) to host the application built throughout the tutorial. When I had that up and running (on Digital Ocean) I realized I could now revisit the Uber API project. I did… and here’s how I did it. I’m going to write the remainder of this post as my current self writing directions to my future self who will eventually need to do this again and forget a bunch of the details…
You need 3 things — a Digital Ocean account where you set up the server (CentOS 6), an API key to access the Uber API, and the script to collect the surge price data.
Digital Ocean
Go to DigitalOcean.com. Create an account (if necessary) and create a droplet. For this project, use a CentOS image and since the computing requirements are minimal choose the $5/month option (512MB CPU / 20GB storage). Go with the default on the rest of the options. Once the droplet is created and Digital Ocean tells you “You’re Awesome”, go to Access and change the root password. Next, copy the IP Address, open the terminal on your laptop, and ssh into the server by typing…
ssh root@162.xxx.xx.xxx
If you get a warning message about authenticity and RSA key fingerprint, continue by typing ‘yes’. Once you see something like this… [root@centos-512mb-nyc4-50 ~]# … you are good to go. It’s worth setting up a new user and the SSH key for more secure (and easy) login if you have time by following this Digital Ocean tutorial. I was more than inclined to do that after logging in several times as the root user and seeing something like this…
![]()
Before moving on to the Uber API, you need to install Python, pip, and virtualenv on your OS — the best thing to do is follow this Digital Ocean tutorial. This can get a bit hairy. Some notes for you…
First, you might notice that ‘No package zlib-dev available’ occurs (as of the date of this article) when installing the optional development tools, you can leave it alone for now until you / if you get stuck ahead (in this mini project I assure you it won’t). Second, after you’ve installed virtualenv you can create a new environment (using the generic name of ‘venv’ for this virtual environment) like so…
virtualenv venv # not strictly necessary for this project, but good habit
You can leave this alone for now and come back to it later…
exit
Uber API
You are going to start by creating (or logging into) your Uber account at https://developer.uber.com/. Register a new app using the Rides API. You can use anything for name and description and agree to the terms (after you have read them). What you’ll need is the server token. In order to figure out the next step, I used Jon Sadka’s blog post… and supplemented with the Uber API documentation. Ultimately, you need the following string of text (replace your server token where it says PASTEYOURSERVERTOKENHERE to call the Uber API and have it return pricing data…
https://api.uber.com/v1/estimates/price?start_latitude=40.7506start_longitude=-73.9939&end_latitude=40.7300&end_longitude=-73.9950&server_token=PASTESERVERTOKENHERE
If you sub your server token into the end of that string and paste the url in a browser window, you should end up looking at something like this…
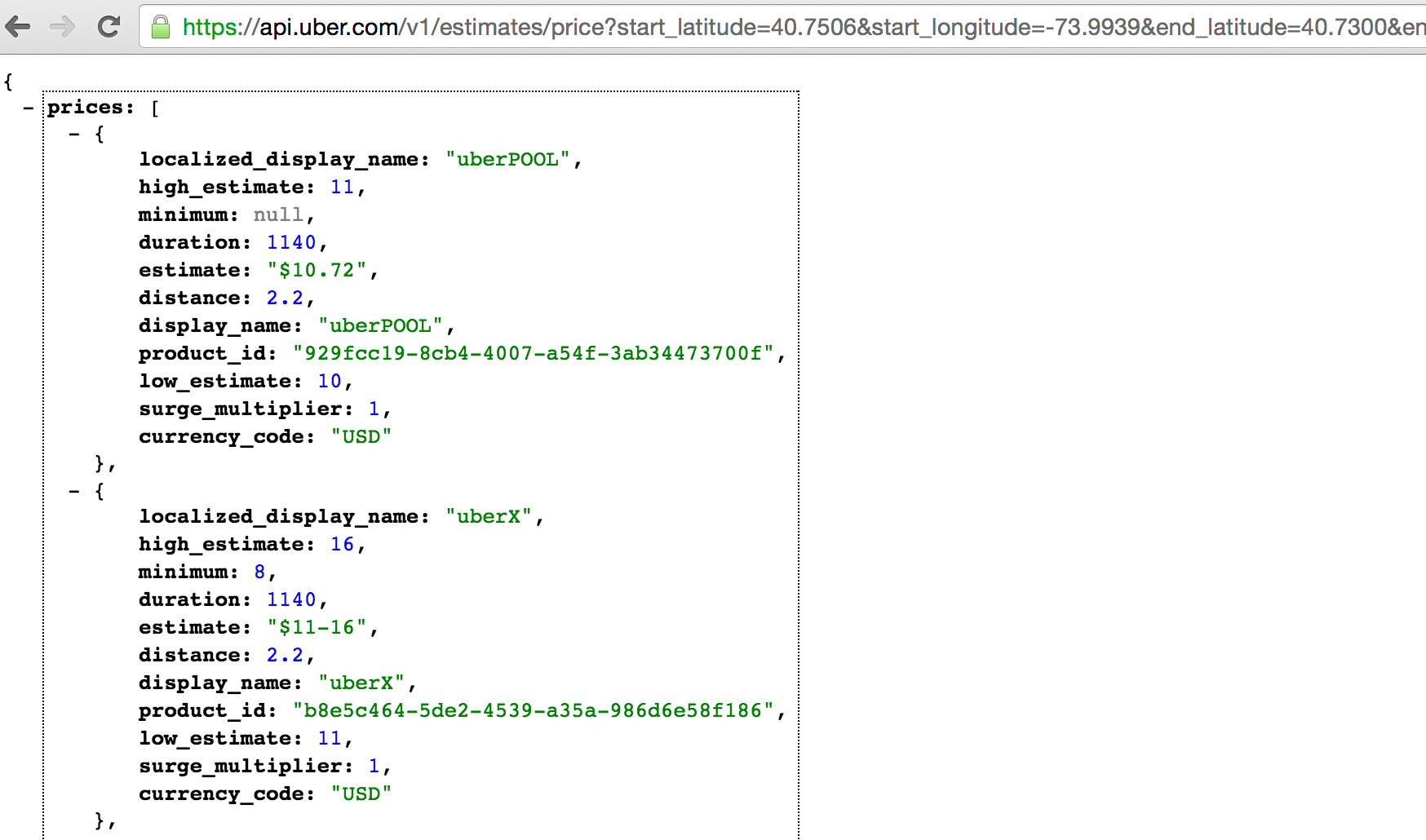
That’s the data. You notice the line that says surge_multiplier: 1. That’s what you want. When demand outpaces supply of drivers, that metric will rise to 1.2 or 2.0 or even higher depending upon the imbalance in the market at that moment. You now have the call to Uber and you know it returns data to you. Write the python script and build the dataset.
Building the Dataset
The script should simply call the Uber API and write the result to a text file in the form of a dictionary. The key is the datetime of the call and the value is the data returned by Uber. Here is what your script could look like for Uber rates between Penn Station and NYU.
#!/usr/bin/python
# file calls uber API and stores result in dictionary
# Penn Station
# lat = 40.7506
# lon = -73.9939
# 40.7506, -73.9939
# NYU
# lat = 40.7300
# lon = -73.9950
# 40.7300, -73.9950
# used to read and write data to file
import os
import os.path
# used to call Uber API and translate results
import requests
import json
# used to identify current date and time
import datetime
call = "https://api.uber.com/v1/estimates/price?start_latitude=40.7506&start_longitude=-73.9939&end_latitude=40.7300&end_longitude=-73.9950&server_token=PASTEYOURSERVERTOKENHERE"
# call the API
r = requests.get(call)
# define datetime to the nearest minute
now = datetime.datetime.now()
now = now - datetime.timedelta(minutes=now.minute % 1,
seconds=now.second,
microseconds=now.microsecond)
# store results of API call in dictionary where
# key is datetime and value is result of call
result = {}
tempdata = r.json()
result[now] = tempdata
# write result to text file
if os.path.isfile('uberData.txt'):
with open('uberData.txt', 'a') as f:
f.write('\n')
f.write(str(result))
f.flush()
else:
with open('uberData.txt', 'a') as f:
f.write(str(result))
f.flush()
At this point you need to fire up your Digital Ocean server, copy this file into a directory, and setup a cronjob so the file will run on every 5 minute interval of the hour (top of the hour x:05, x:10, x:15, x:20, etc.).
ssh root@162.xxx.xx.xxx source venv/bin/activate # not strictly necessary for this project, but good habit
You need to create the api collector file that you wrote above. The easiest way to do this is manually (later on I talk about rsync which you can use to move this file from your local directory to a VPS directory, but for now since the script is short just type it out). Here is a good refresher on vim editor if you need it.
# create the file, open in vim editor touch UberDataCollector.py vi UberDataCollectory.py # when editor open, press 'i' to insert # and retype the file # when done, press 'esc' and the ':x' # to save and exit
The next step is to set up a cron job. Here is the Digital Ocean article with the details.
# open the cron editor... crontab -e # and insert the following... 0,5,10,15,20,25,30,35,40,45,50,55 * * * * cd /home/username python UberDataCollector.py # don't forget to replace 'username' and the filename with your own
You could try to use a more concise syntax, but the one above is as clear as day – run our data collector every time the minute of the hour becomes a multiple of 5 (or at the top of the hour).
At this point, you can logout of your session and come back in a week to retrieve the data file. Sidebar – you’ll probably want to test this out in shorter intervals to make sure everything is working properly) Speaking of retrieving the data, how would you get a file (or files) from the VPS to your local machine in order to do an analysis? Use rsync. If rsync is not already installed on your VPS or on your local machine (I’d be surprised), you can use yum -y install rsync on the VPS and brew install rsync on your local machine. Open a terminal on your local machine and type:
# sub in both the VSP directory where the data file is # and the directory on you local machine where you want it to go rsync -a uber@162.xxx.xx.xxx:/home/username/theFileName.txt localDirectory
Cost
If you remember from above when setting up the VPS, you chose the $5/month option that allowed for 512MB CPU / 20GB storage. Running this script every fine minutes won’t get you anywhere near that 512 limit. How do I know? Since the file only runs for about 2 seconds, I put a time.sleep(60) line at the bottom of the file and ran it in my console (locally). In another terminal, I used the ‘top’ command which displays processor activity. In the MEM column for this activity, when I am running the script, it doesn’t go above 20MB so I know I am well within my 512 limit.
Then, for storage, I simply look at a file with only one API request results in it which is roughly 2.4KB. I am collecting data every five minutes over the course of a week which is 12 observations an hour * 24 hours per day * 7 days = 2,016 observations. 2,016 * 2.4K = 4.83MB. That’s 0.025% of your storage limit. You should be good to go at the $5/month option. In fact, it may be worth re-exploring some of AWS’s free options at this level of usage if this is going to be a regular thing. I do believe Digital Ocean is such a good starting point to learn this stuff because the blog / articles on Digital Ocean are very clearly written and very helpful.
At any rate, when your droplet is up and running you can also check these metrics as you go. You can monitor CPU utilization over time with the graphs in your Digital Ocean account page. If you want to view RAM usage, go into your server console and type ‘free -m’. To see how much disk space you are using ‘df -h’.
Summary
There are a few things that can be improved upon. First, you can take further steps to protect your server on Digital Ocean. Since there was no super sensitive information in this project I kept it relatively simple. Second, you can probably make more efficient calls to the Uber API targeting only the surge price data rather than the entire object. Since the dataset was small-ish I just took the whole response. Lastly, setting up and running the server on Digital Ocean cost $5 which is probably more than you need for a project like this. I recommend checking out AWS and exploring the free option – Grant McKinnon has a great post on how to do it.